Setting up
-
You need to understand the purpose of the database
-
This means knowing
- What data it needs to store
- How the data is going to be used
- What the relationships are between different pieces of data
-
We start by talking to the customer to get as complete a picture as we can
Entity Relationship Diagram (ERD)
-
Once we’ve spoken to our customer, or even as we speak to our customer, we make an ERD.
-
This shows which entities the system needs to model.
- It also shows the relationships between these entities.
Example: A school has classes that are taught by a single teacher and attended by one or more students. Each class is taught in a single room. Students can study more than one subject but teachers can only teach one subject.
Identify the entities.
- What is an entity is a discussion, not a given. Things that the database needs to track are entities.
- Some entities may be physicalsuch as a teacher—whilst some are just concepts—such as a subject.
Entities: school, classes, teacher, room, students, subject
The school may want additional entities, such as reports, registers, books, invoices etc. It simply depends upon the use case for the database and what the school wishes to track/do with the database.
Some entities may not be needed. So for instance a school would not be required in this database as all data is stored solely for the school—if multiple schools needed to use this database then the school entity might make sense. So we can exclude school from our entity list.
Next, we take all of the entities and think about how they are related to all other entities.
Naming conventions
Entities should be named in a uniform way. The convention is to be consistent, and people typically name everything in the singular.
So we would store classes as class and students as student.
This does not technically matter in terms of database performance or functionality, it’s just something that makes it easier for humans to understand.
Relationships
There are 3 types of relationship possible between entities.
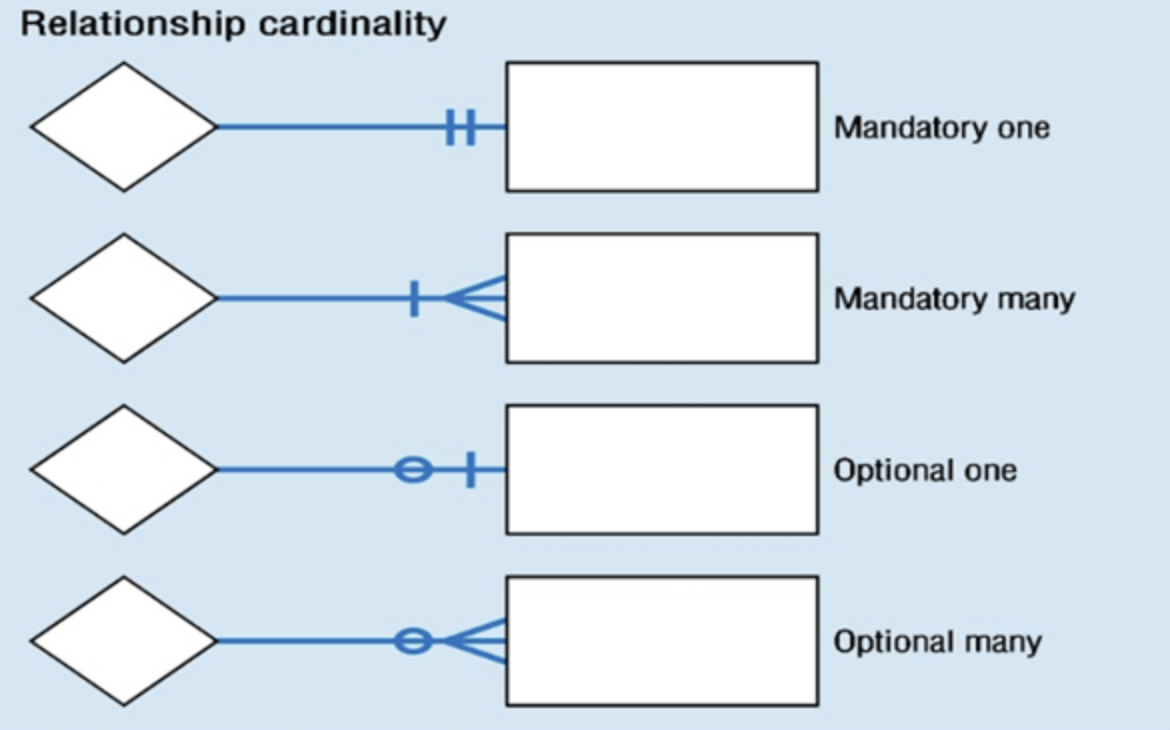
One-to-one
- For each single item a link exists to another single item.
- So one alarm links to one house. An alarm cannot be installed in multiple houses, and the imaginary security company only installs one alarm per house.
One-to-many
- For one single item, a link exists to multiple other items.
- For example, a supplier may have mutliple products.
Heinz is the supplier of baked beans and ketchup. However ketchup and baked beans only have 1 supplier, whilst Heinz has 2 products in this scenario.
Each product can only have 1 supplier.
Many-to-many
- For each single instance, there are links to and from multiple other instances of a different entity.
- A subject can be taught by many teachers, and teachers can teach many subjects.
Caution
Avoid any relationship except one-to-many. It is significantly easier to work with one-to-many and it makes your database more flexible.
Many-to-many relationships are difficult to model.
So we break up the relationship and make a link entity
So instead of having a many-to-many link between subject and teacher, we have a one-to-many relationship between teacher and subject teacher and subject and subject teacher. This reduces wasted space to 0 in our model and also makes queries easier to manage.
With a one-to-one relationship, there is exactly one instance of each entity for each instance of another entity. Although this is OK and does provide the possibility to expand the system in future, it might make sense to combine the two.
So House and Alarm (with a one-to-one relationship) could be replaced with a single entity called Alarm Installation.
Normalization is required to ensure that data is stored in the most proper way. So for any one data point, there is only one way it should be stored.
If the same type of information is stored more than once - ie, product details for an order, then this is a repeating group. It should NOT be stored in the same entity as the order. So you would make a new entity to store the repeating group.
An instance of the repeating group entity will be created for every new line required.
Data Dictionary
- Once we know what the entities are, we need to identify their attributes.
- This means working out what information we need to store about each entity and what data type we need to store this as.
- We would also need to consider, at this stage, what validation rules would be needed for each attribute.
Primary Key Fields
-
For each instance of an entity we need some way of identifying it
- Each pupil needs an ID
- Each car needs an ID
- etc
-
The information we use to identify a single instance of the entity must be unique
-
Sometimes there exists some attribute that fulfils this requirement.
- The VIN on a car for example
-
But often, and sometimes even if an attribute could be used, we want to make our own unique ID.
-
The ID value when seen in the entity that is identifying is called the Primary key.
-
When used in another entity, it is used to link two things together and is called a Foreign key.
-
Sometimes we can’t use a single attribute to uniquely identify an instance of an entity.
-
In this case we might need to use two or more attributes.
-
This is called a Composite Key (sometimes a Compound Key).
-
A key can be a primary key and a foreign key.
Keys are how we create relationships in a relational database.
Normalization
- We’ve identified the entities and the data that we think should be stored in them.
- Normalization is the process of ensuring that the data is stored in the most efficient way possible.
- When we’re finished, the data is said to be in Third Normal Form.
- First and Second Normal form are not relevant.
Important
A database is in third normal form if every attribute in every entity is dependant on the key, the whole key, and nothing but the key.
Reference to the key is primary or composite key.
Third Normal Form
- We make sure that each entity only has attributes that depend on the whole key.
- Remove any repeating groups.
- We make sure that we have no many-to-many relationships.
- All data is atomic
- Atomic meaning that no attribute contains more than one piece of information
A name is not atomic because it contains at least 2 pieces of information “FirstName” and “LastName”. Storing it just as “Name” would be possible, but would greatly complicate things later on.
It is also possible to break information into more pieces of information than necessary. For example, if your address was “23 Chester Close”” you might try and break it down into “23” and “Chester Close”. However as it is the first line of their address, it is a single piece of information. This does depend upon use case of course, because if you just want to find people living on a certain street, then you might wish to collect street names as seperate entities.
Reasons for normalization
-
Eliminate duplication
- Make sure each piece of information is only stored once
- Only store the customer details once
- Don’t store the same details in another table
- Link back to the customer entity with a foreign key
- Make sure each piece of information is only stored once
-
Eliminate redundancy
- Storing the same information twice but in different forms
- Storing an engine power in horsepower and torques
- Storing a length in meters and feet
- Storing the same information twice but in different forms
-
Eliminate anomalies (insertion, update or delete)
- If there are no duplications, we can’t get anomalies
- I have a customer’s address stored twice in two entities
- When I update this information I only update one instance
- If there are no duplications, we can’t get anomalies
-
Eliminate inconsistencies
- An inconsistency is the result of an anomaly.
- Having had the anomaly mentioned above I now have two addresses for the same customer
- How would I determine which one is correct?
- An inconsistency is the result of an anomaly.
-
To improve database performance
- Reduce storage requirements
- No duplication means less data
- Increase operation speed (lookup, update, delete)
- No duplication or redundancy makes operations simpler and use less resources
- Reduce storage requirements